A transformer is a neural network architecture. It uses self-attention mechanisms to process sequential data in parallel, replacing old recurrent models like RNNs.
First the data is divided into chunks. To process data in parallel means attending all the chunks of that data simultaneously. You can think of attention as capturing the context of the whole data and self-attention as: each chunk goes through all other chunks, which will help it understand its own meaning, hence self.

So now let us go through the whole process and understand what exactly happens and how.
So first, we give a sentence to the model and the model breaks that sentence into chunks, which are known as tokens, and this process is known as tokenization. Like for example, if in the GPT-5.x model we give the sentence “this is tokenization”, it breaks it down into 4 tokens: ‘this’, ‘ is’, ‘ token’, and ’ization’. You can play with the tokenizer for the OpenAI’s models at → https://platform.openai.com/tokenizer.
# First install tiktoken -> !pip install tiktoken -q
import tiktoken
import numpy as np
text = "this is tokenization"
tokens = tokenizer.encode(text)
print(f"Text: '{text}'")
print(f"Tokens: {tokens}")
print(f"Number of tokens: {len(tokens)}")
print("\nToken breakdown:")
for token in tokens:
print(f" {token} → '{tokenizer.decode([token])}'")NOTE : The second and third token are : ‘ is’ , ‘ token’ and not ‘is’ , ‘token’ (notice the space).
Every token has its own unique ID. These are the tokens that you see as one million token limits or 128k token limit in various models and these tokens are what you pay for when buying an AI subscription.
So now we have successfully converted our sentences into an array of some token IDs like “this is tokenization” → [576, 374, 4037, 2065]. But these IDs are random. They don't know what they represent. So we need to know what these IDs mean. Here is where embeddings comes into the picture.
So in general embedding means placing something inside another. In machine learning embedding means placing the meaning or the context of something into some identifier. In more technical terms, embedding is a collection of vectors which represent different aspects through which a token can be represented OR embedding is a mapping of tokens into vectors in a continuous space, where each vector encodes or represents the semantic or contextual information.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
# Simulating an embedding matrix
vocab_size = 50000
embedding_dim = 768 # GPT-2 size
# Random embedding matrix (in reality, this is LEARNED)
embedding_matrix = np.random.randn(vocab_size, embedding_dim) * 0.02
print(f"Embedding matrix shape: {embedding_matrix.shape}")
print(f" → {vocab_size:,} tokens")
print(f" → {embedding_dim} dimensions per token")
print(f" → {vocab_size * embedding_dim:,} total parameters just for embeddings!")
text = "this is tokenization"
tokens = tokenizer.encode(text)
print(f"Text: '{text}'")
print(f"Token IDs: {tokens}")
print()
# Look up each token's embedding
for token_id in tokens:
embedding = embedding_matrix[token_id]
print(f"Token {token_id} ('{tokenizer.decode([token_id])}')")
print(f" → Embedding shape: {embedding.shape}")
print(f" → First 10 values: {embedding[:10].round(3)}")
print()Since now that we understand vectors, we can also conclude that similar meaning tokens will be nearby vectors in the multi-dimensional space.
So till now we know that we give input to the model. The model first breaks down that input into tokens. Those tokens are converted into embeddings. But now we have a new problem as we know that the transformer model processes every token parallelly so it would be really hard for the model to understand the sequence of the words. The model sees the set of words not the sequence. For the model “the lion killed the elephant” and “the elephant killed the lion” are same. This “Permutation Invariance” leads to the loss of the meaning of the input. So it is needed to know the sequence of the words in the input.
For knowing the token's position in a sequence, we use the following two sinusoidal equations:
PE(pos, 2i) = sin(pos / 100002i/dmodel)
PE(pos, 2i+1) = cos(pos / 100002i/dmodel)
Where pos is the token's position and dmodel is the embedding dimension.
These values are deterministically calculated using these formulas and then added to the token's word embedding. This way the model knows not just what the token is but also where it appears in the sequence, with different dimensions encoding.
Understand this by looking at the following graph :
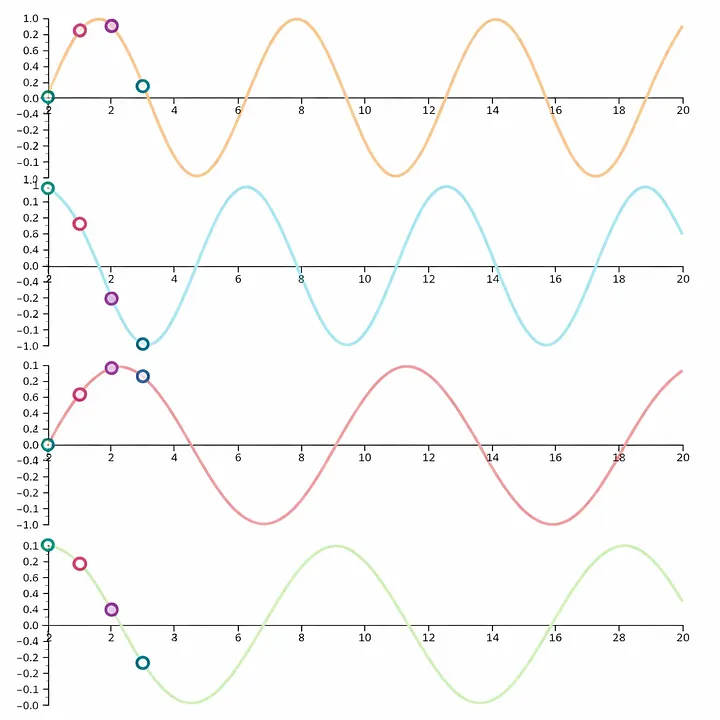
Here at position 0 the combination of the values of these four waves creates a unique value. If we go a little forward then we will get another four values from the waves that will create a unique set of values.
Since we know that when the sentence was converted into tokens it was like an array of tokens. The first token is assigned the first set of values from these graphs, the second token is assigned the second set of values and so on. This is how the model knows the position of the token as these values are fixed and pre-calculated. The purpose of using multiple frequencies is to create a unique set, or let's say fingerprint, for every single position in a very high dimensional space.
RECAP : Text → Tokens → Token IDs → Embeddings → + Positional Encoding → Final Input Matrix
Now each token has meaning and position. The next question is: how do tokens interact with each other? And we will get into that in the next part.